RETOUR AU TERMINAL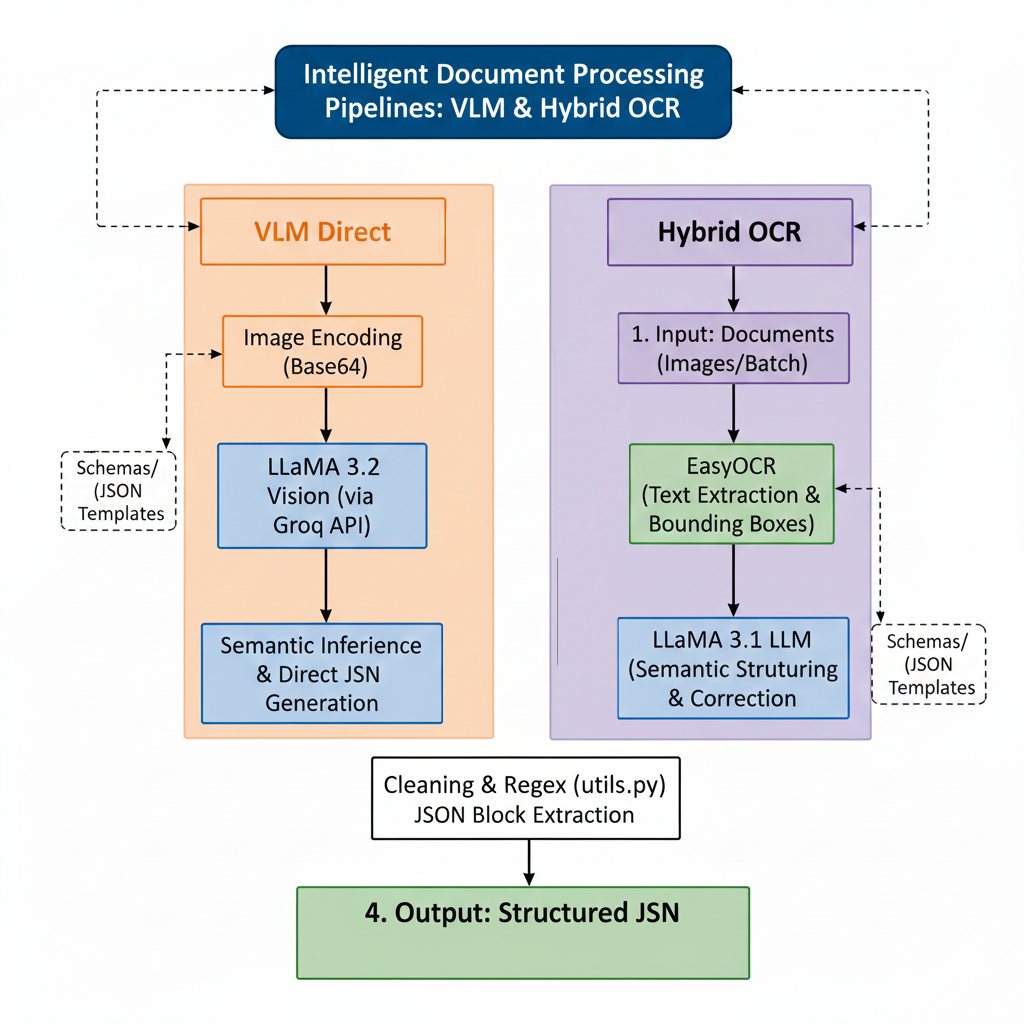
01. Contexte
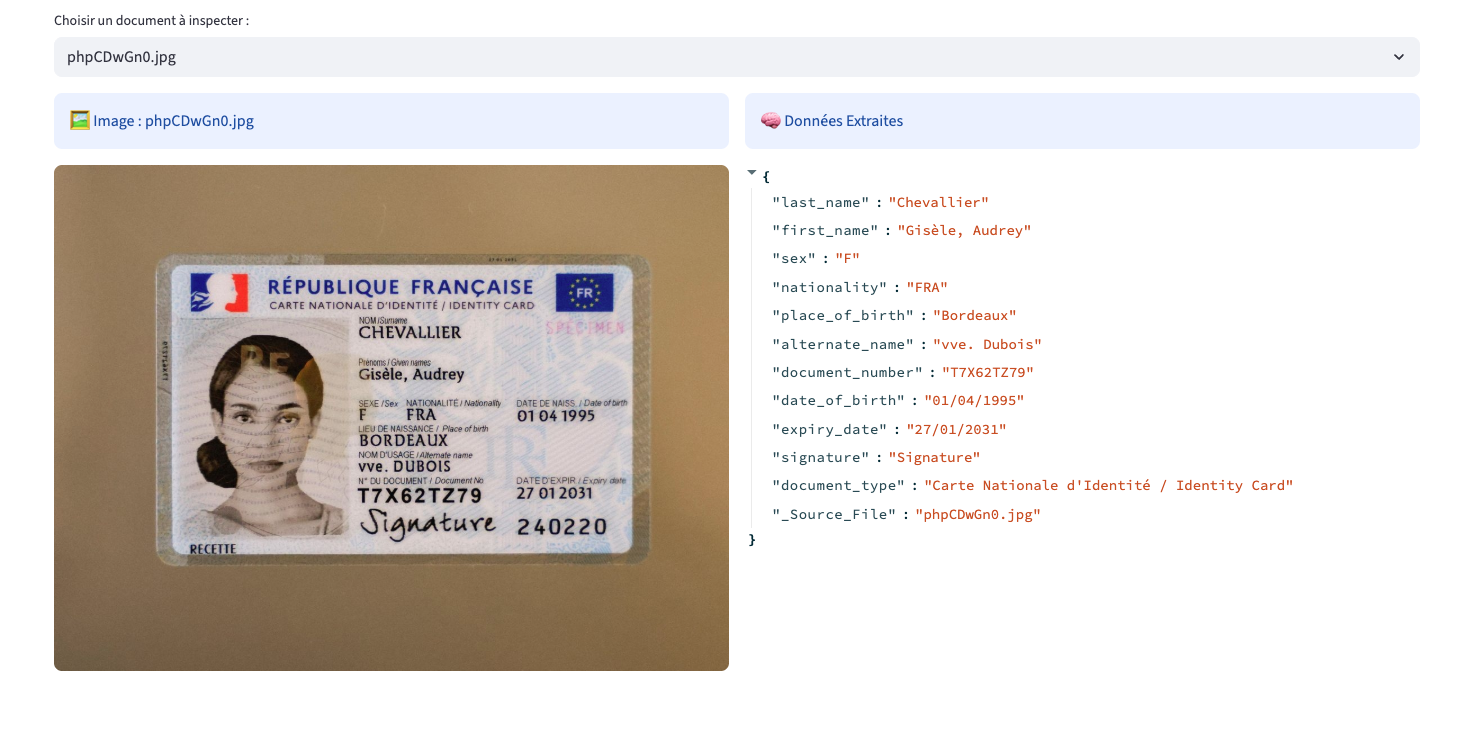
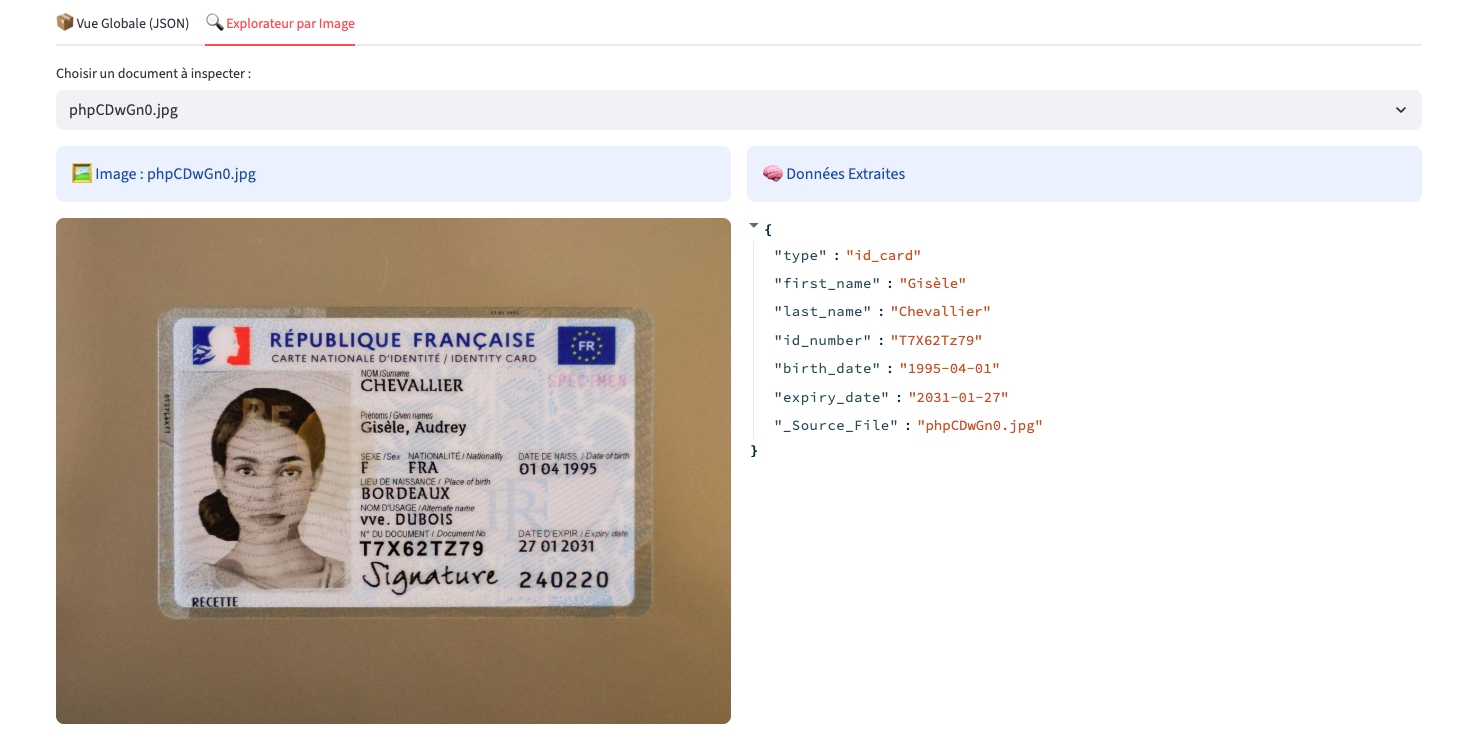
Ce projet vise à transformer des documents non structurés (factures, cartes d'identité, etc.) en données structurées. L'enjeu était de dépasser les limites de l'OCR classique en intégrant une compréhension sémantique via un modèle Llama 4 Vision
02. Architecture
- VLM Direct Pipeline : Utilisation de Llama 4 Vision pour une extraction 'Vision-to-JSON' sans étape d'OCR intermédiaire
- Hybrid OCR Engine : Pipeline combinant EasyOCR (locale) et Llama 3.1 pour la restructuration sémantique
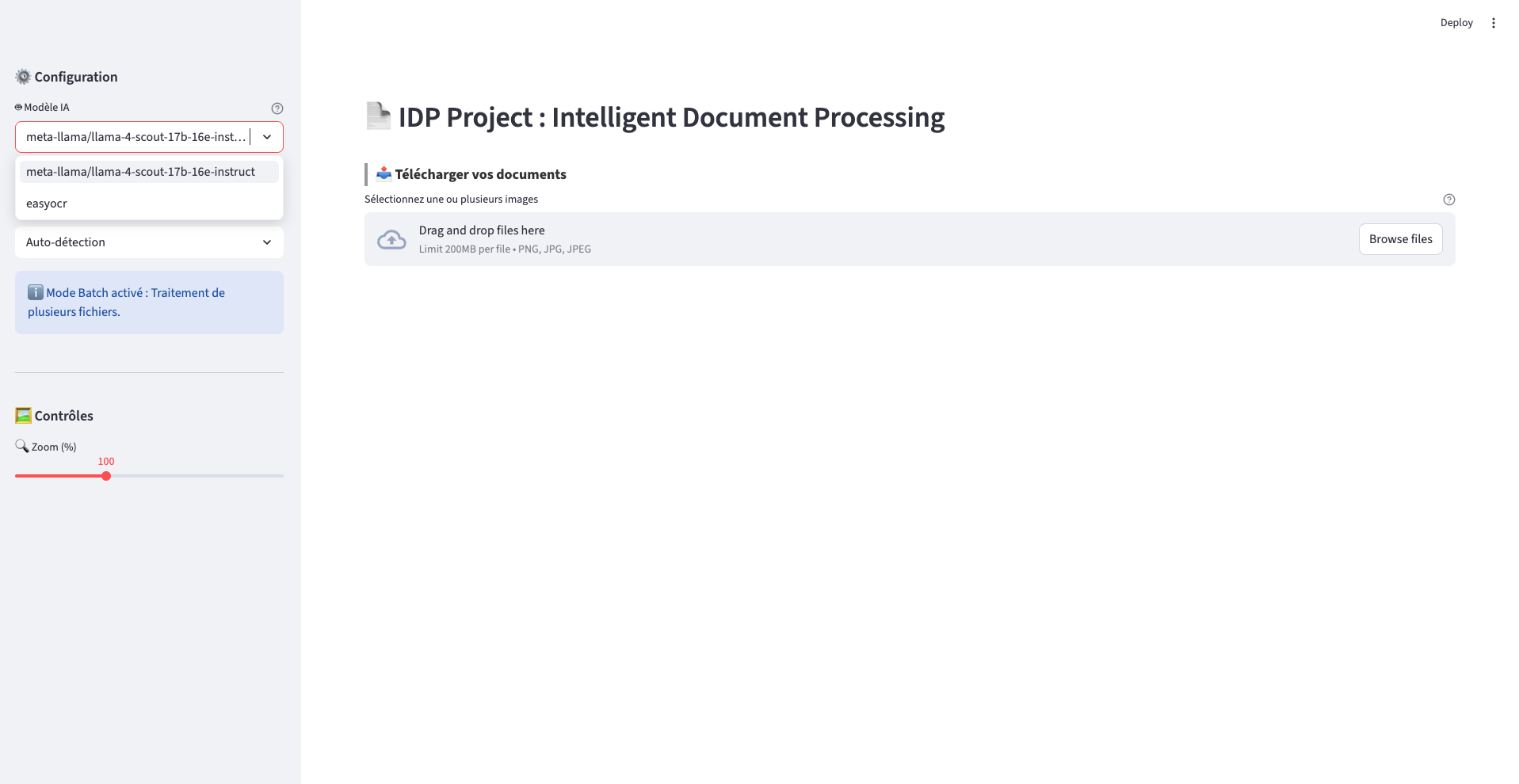
- Orchestration : Interface Streamlit asynchrone gérant l'upload/download des documents et les retours API en temps réel
03. Fonctionnalités
Performance Record : Temps de traitement moyen de 1.72s par document
Mode Automatique : Capacité d'extraction sur des formats inconnus sans schéma prédéfini
Scalabilité : Architecture permettant l'ajout de nouveaux types de documents par simple dépôt de schémas JSON.
Correction Sémantique : Capacité du LLM à corriger les erreurs de lecture physique de l'OCR en s'appuyant sur le contexte.
04. Démo Visuelle
Agrandir l'image
Agrandir l'image
Agrandir l'image