RETOUR AU TERMINAL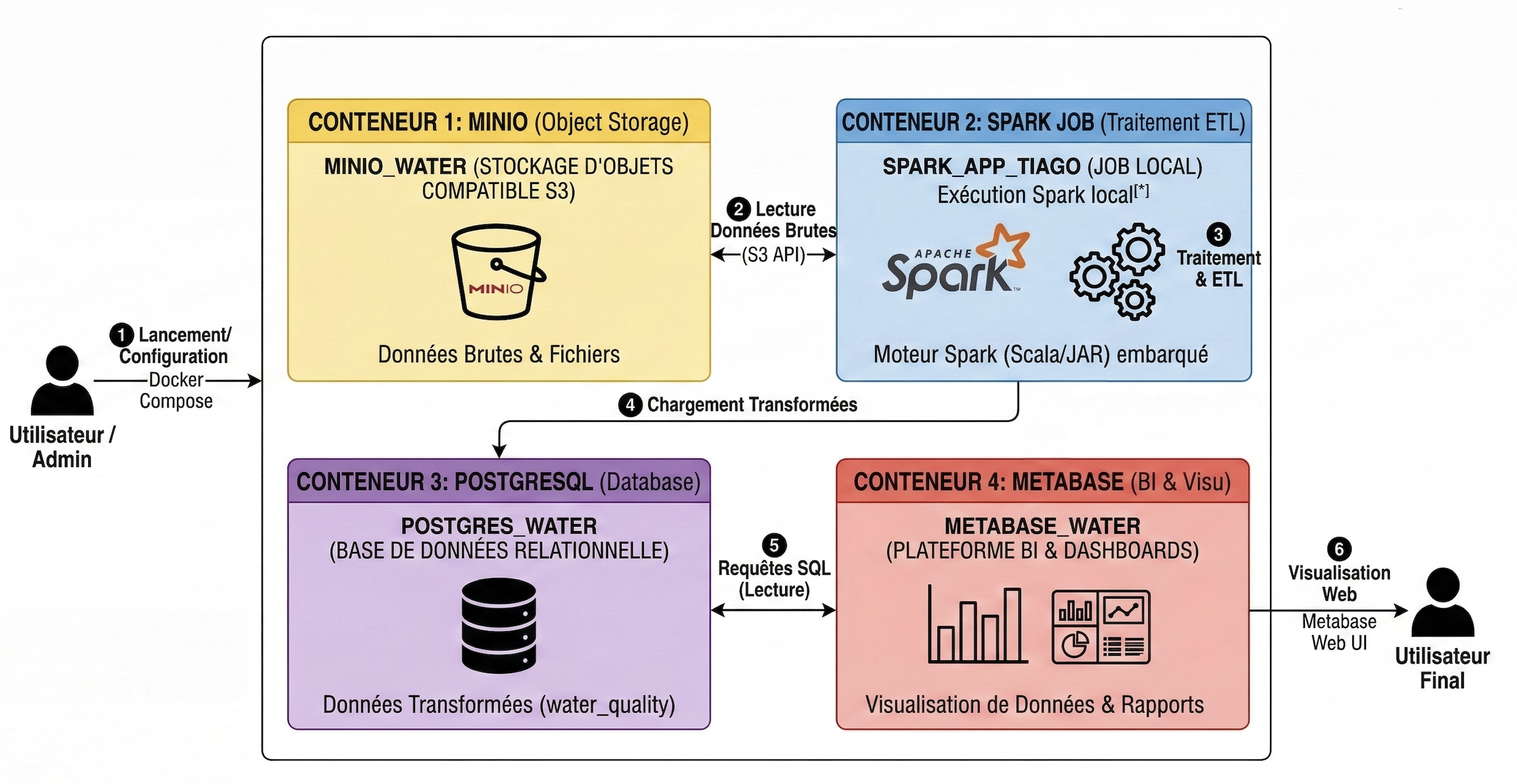
01. Contexte
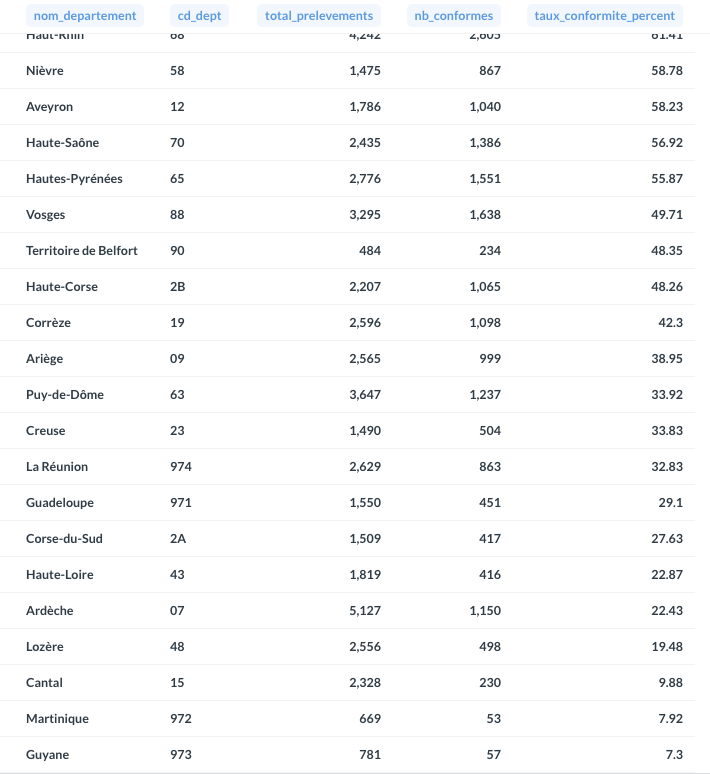
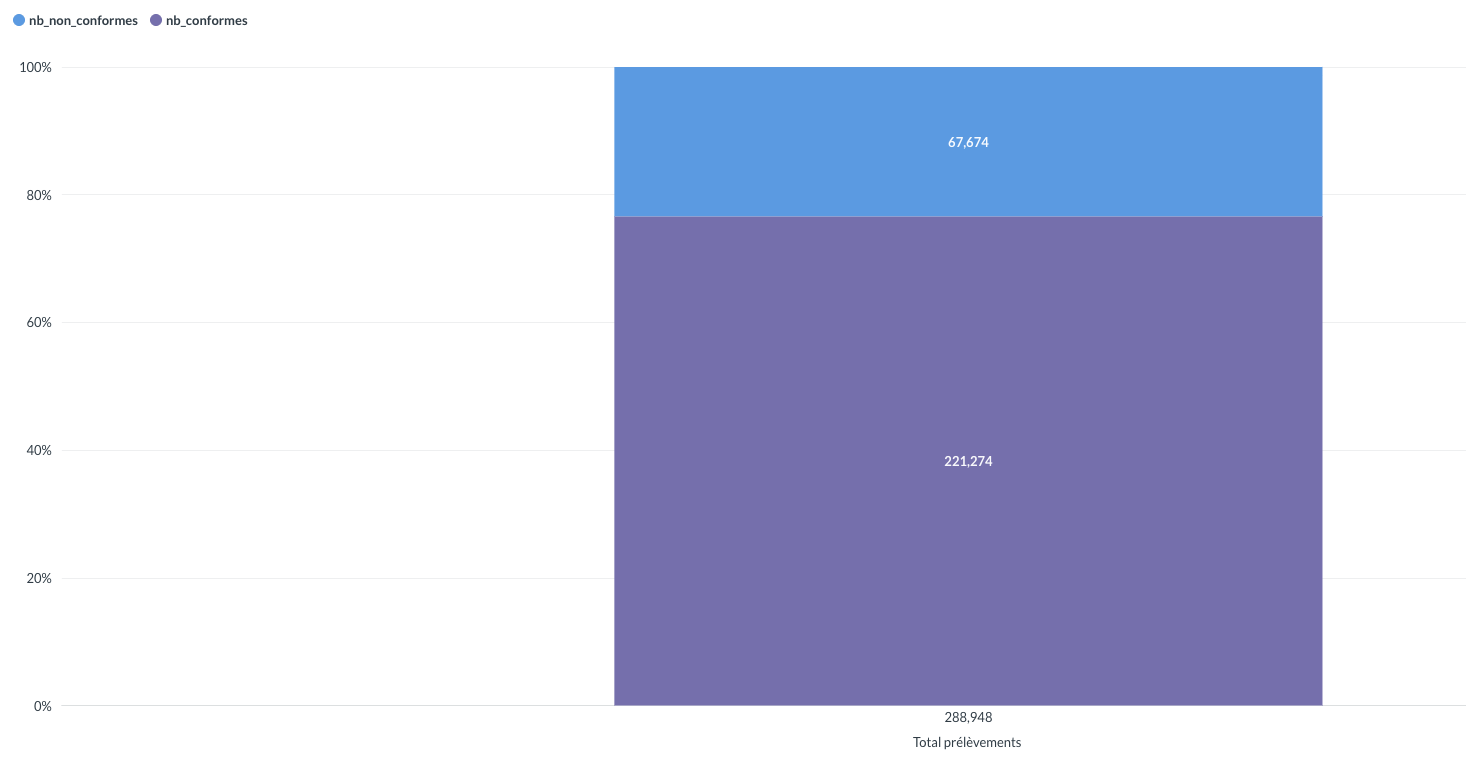
Ce projet implémente un pipeline ETL complet pour analyser les résultats du contrôle sanitaire des eaux distribuées en France. L'objectif est d'extraire des volumes importants de données publiques, de les transformer et de les rendre exploitables pour de l'analyse décisionnelle
02. Architecture
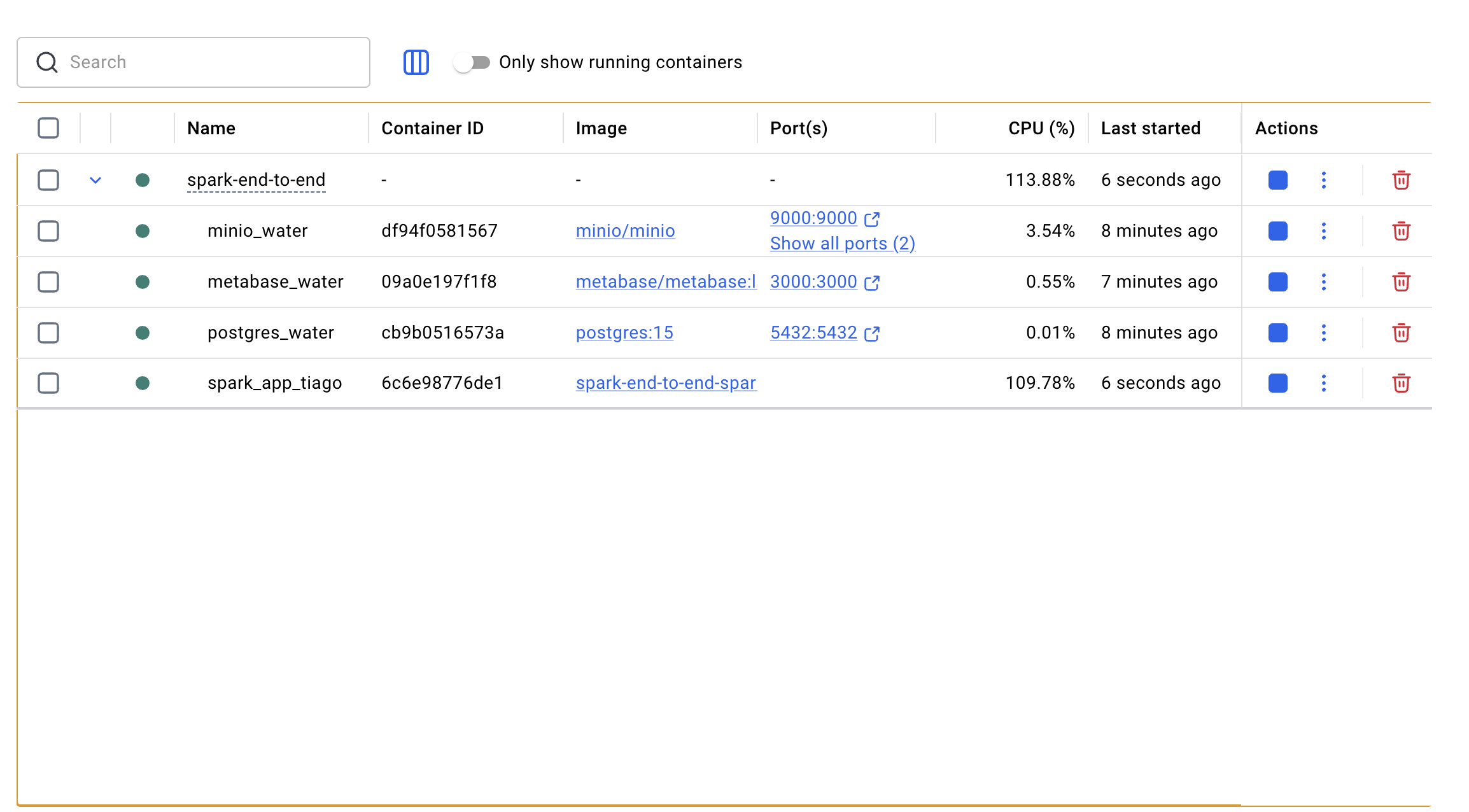
- Orchestration Docker : Déploiement d'un écosystème de 4 conteneurs (Spark, MinIO, Postgres, Metabase) via Docker Compose
- Build System : Utilisation de SBT pour générer un JAR incluant toutes les dépendances
- Processing (Scala/Spark) : Utilisation de Scala pour le nettoyage, le filtrage et l'agrégation statistique des prélèvements
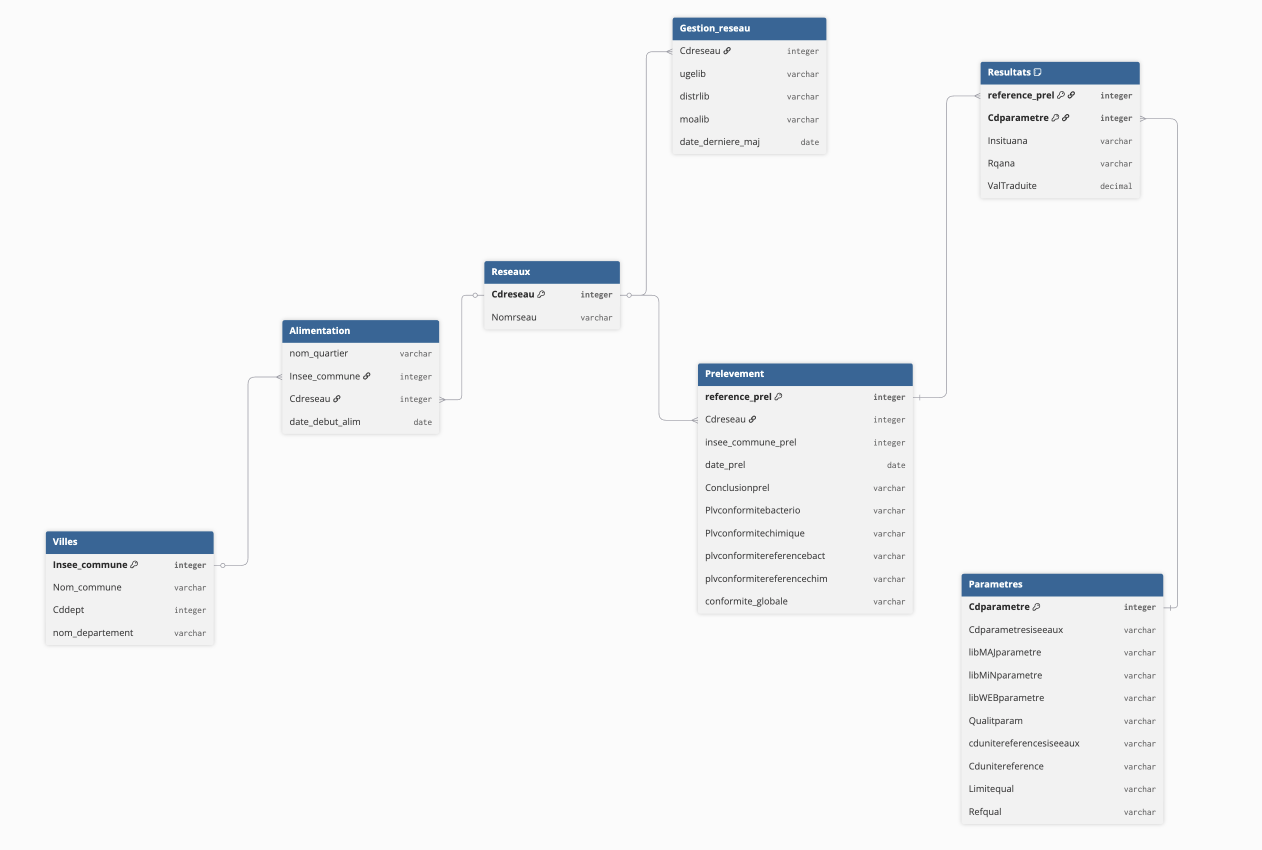
- Loading (PostgreSQL) : Chargement des données transformées et structurées dans une base relationnelle PostgreSQL
- Data Visualization : Connexion de Metabase à PostgreSQL pour la création de tableaux de bord de suivi sanitaire
03. Fonctionnalités
ETL perfomant : Exploitation de la puissance de Scala pour traiter des jeux de données nationaux
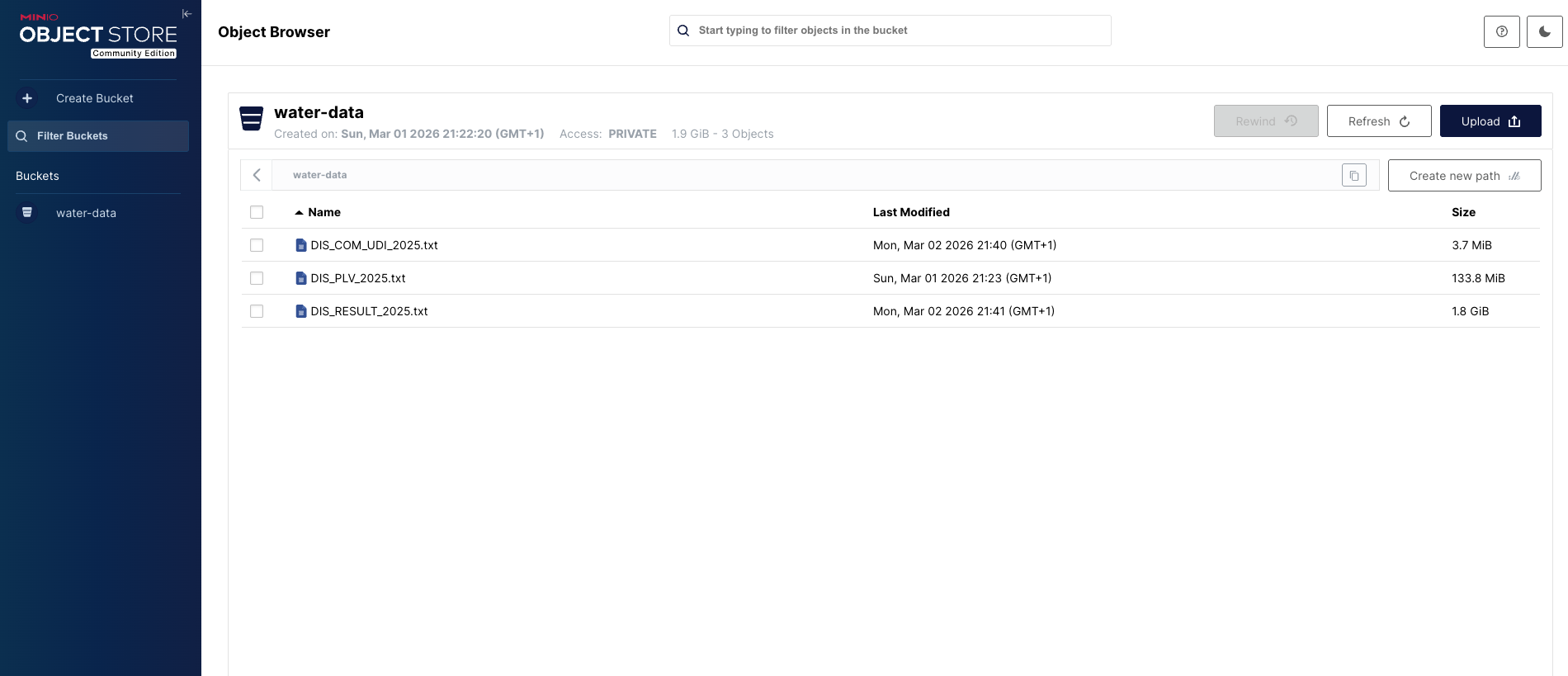
Storage S3-like : Utilisation de MinIO comme zone de dépôt pour découpler l'ingestion du traitement
Conteneurisation : Gestion simplifiée des dépendances et du déploiement via Docker
04. Démo Visuelle
Agrandir l'image
Agrandir l'image
Agrandir l'image
Agrandir l'image
Agrandir l'image