RETOUR AU TERMINAL
01. Contexte
Modernisation et déploiement de l'écosystème HydroSpark sur Azure. L'objectif est d'industrialiser l'ingestion et le traitement de données massives tout en offrant une interface de visualisation fluide et scalable.
02. Architecture
- Ingestion (Spark) : Pipeline de traitement distribué en Scala pour la structuration des flux de données nationaux
- Calcul Api : Déploiement du backend NestJS sur Azure Container Apps pour une gestion dynamique des ressources et une scalabilité automatique
- Management des Données : Utilisation d'Azure Database pour PostgreSQL pour le stockage structuré et performant
- Frontend (Static Web Apps) : Hébergement de l'interface React pour une diffusion rapide des indicateurs sanitaires
- Intégration Cloud : Connectivité optimisée entre les services managés pour minimiser la latence
03. Fonctionnalités
Performance Scalable : Architecture conçue pour absorber des volumes croissants de données sans dégradation de la performance
Automatisation CI/CD : Déploiement automatisé via GitHub Actions pour une livraison continue et sans erreur
Haute Disponibilité : Utilisation de services managés Azure garantissant une disponibilité maximale et une maintenance simplifiée
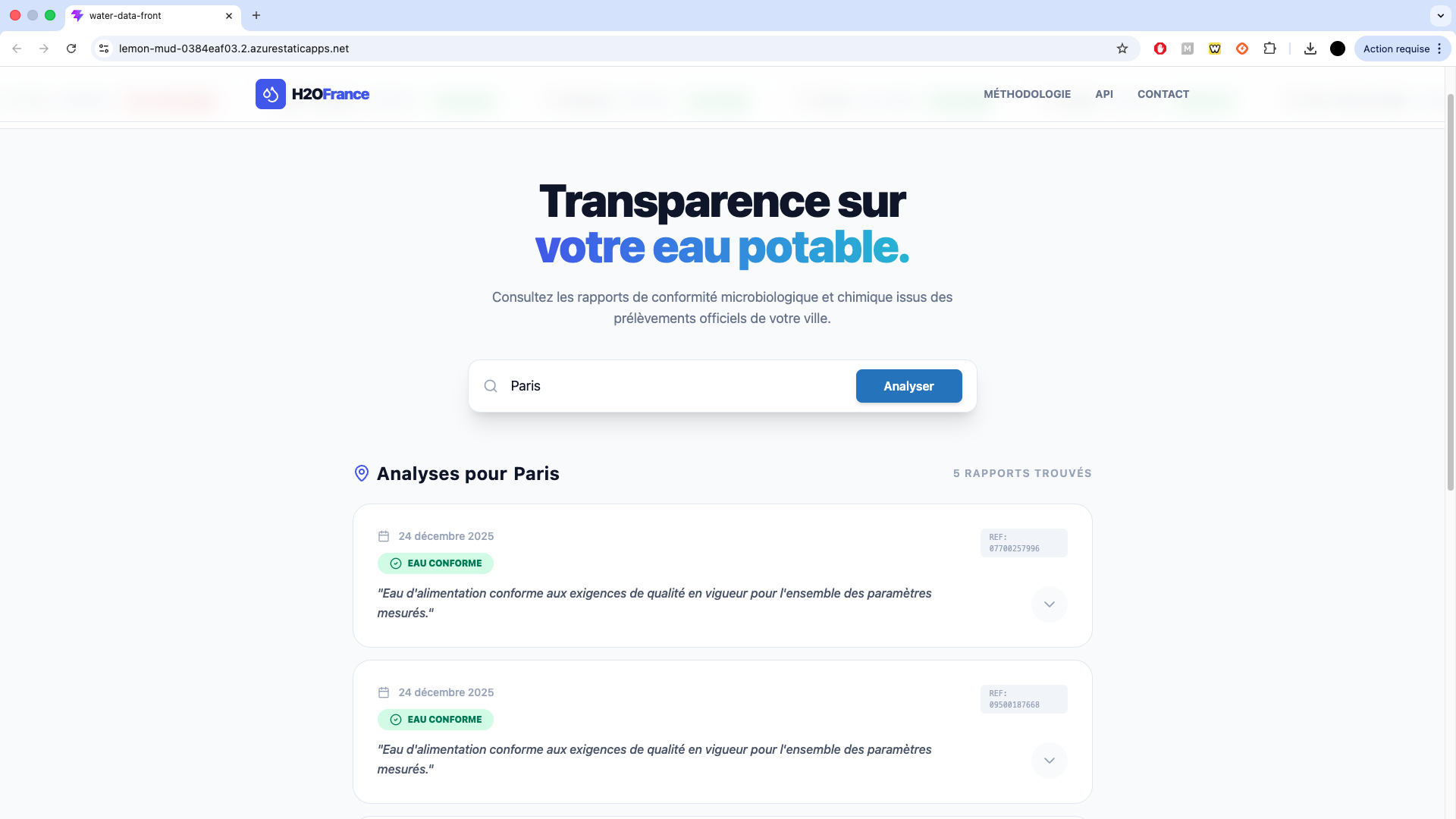
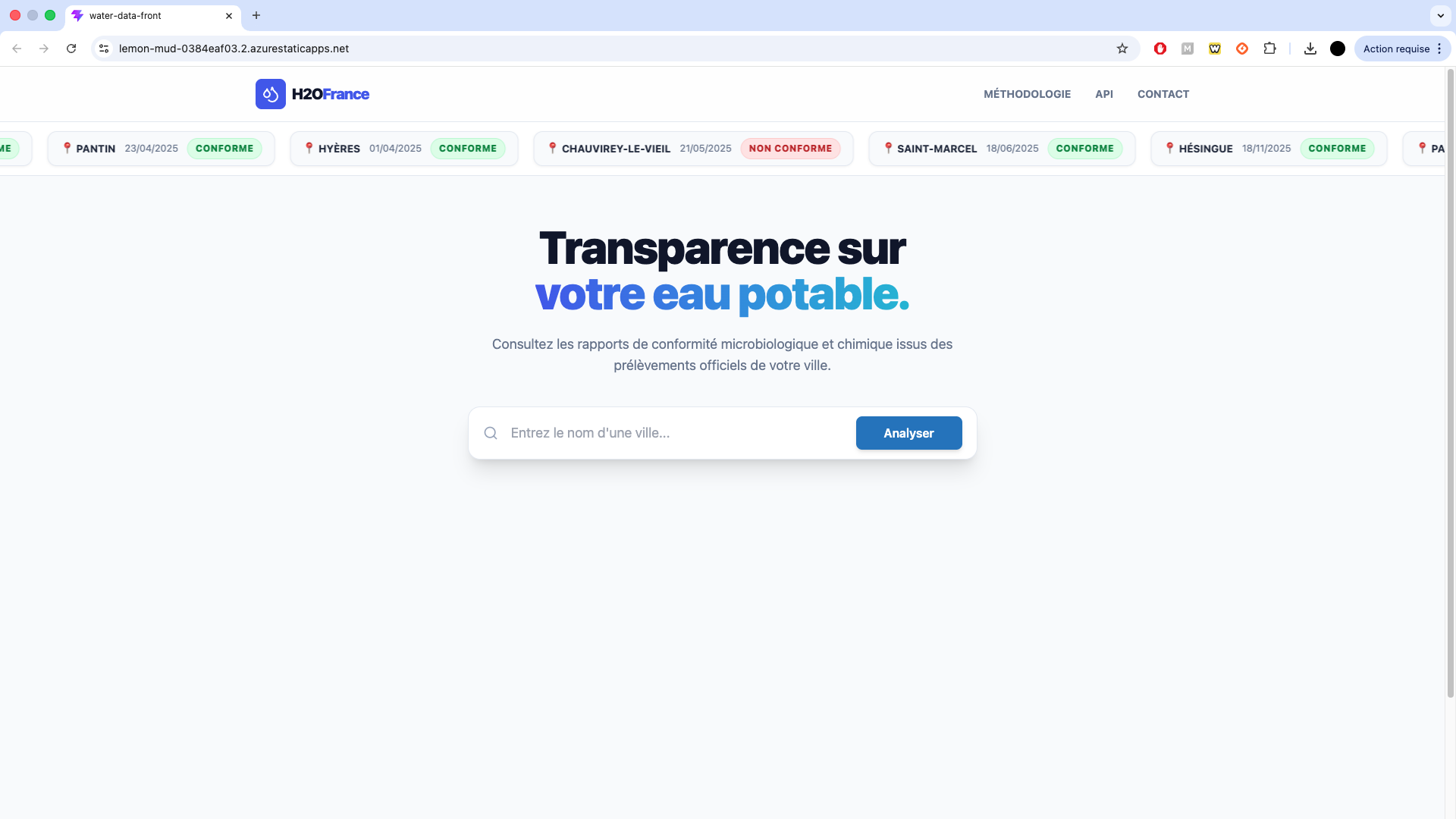
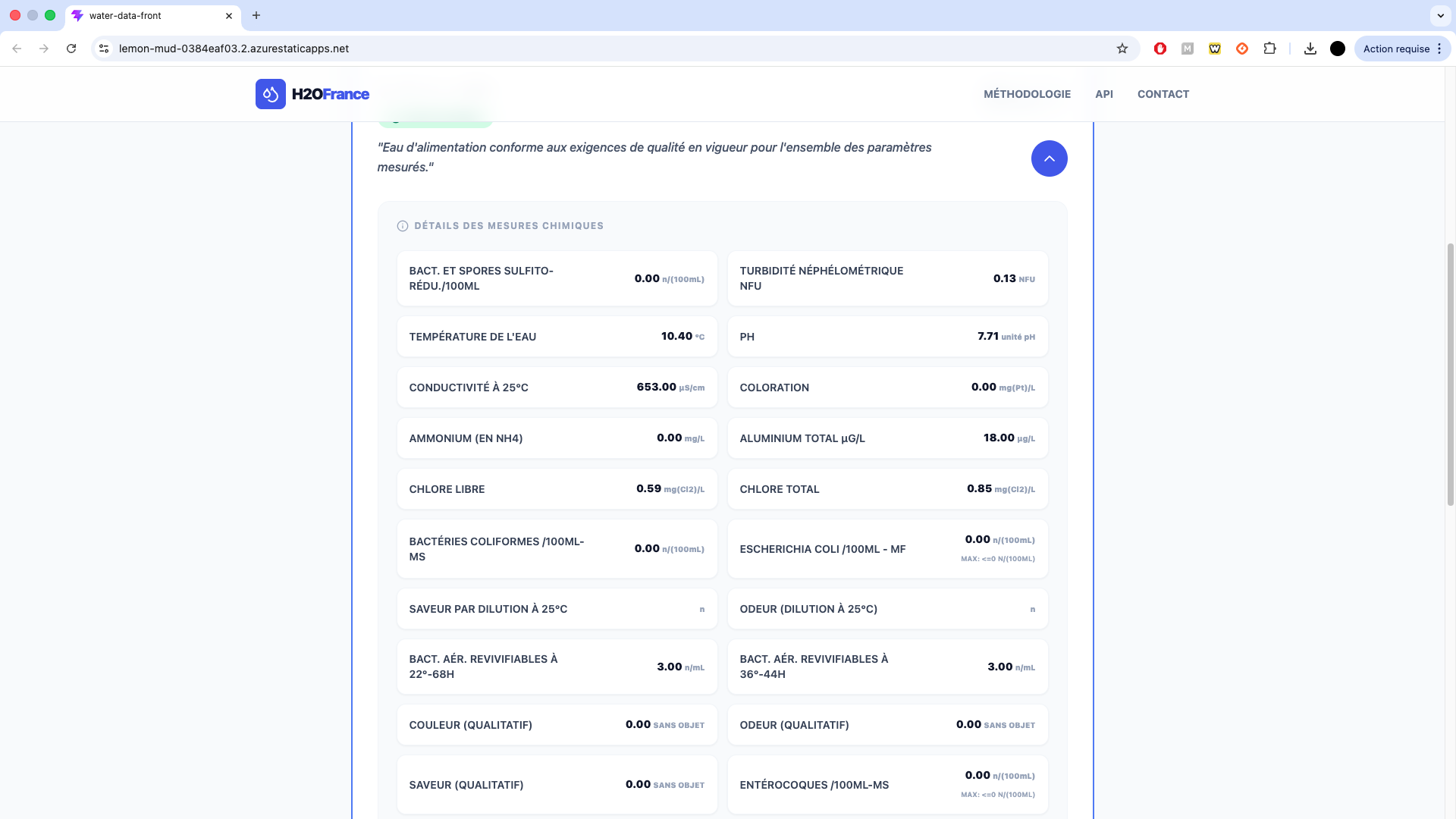
04. Démo Visuelle
Agrandir l'image
Agrandir l'image
Agrandir l'image